HDA学习总结
开发背景
随着业务系统的运行,伴随的业务数据也会日积月累的越来越多,占用的数据库空间也会越来越大,如果不及时清理,会降低系统数据的读写速度,影响系统的性能。而当系统性能下降到一定程度,就会影响到系统的正常运行,导致业务处理能力下降,甚至导致业务中断无法运行。
因此,系统需要一个通用的、相对独立的数据归档工具来定期清理业务数据,减小系统在线数据的大小,维持系统的运行效率。
系统架构
HDA全称是Historical Data Archive。
HDA归档主要主要包含两个数据表,一个是归档配置表另一个是归档日志表。归档任务是通过定时任务定时来触发的,定时的具体时间是在Apollo中进行配置的(task.deadline.time)。到定时时间了,系统就会自动触发归档,来查询归档配置对数据进行归档。归档配置表主要包含表名、表的所属用户、数据库名、归档标志、清理标志、基准时间字段、归档数据间隔天数等。
通过配置表的这些字段可以判断出那些表的那些数据需要进行归档,需要注意的是归档数据只支持分区表,因为非分区表中保存的一般为状态类型的数据,通常情况不需要使用工具进行清理,如果有清理需求由运维人员进行手动清理。
业务数据的生命周期如下图:
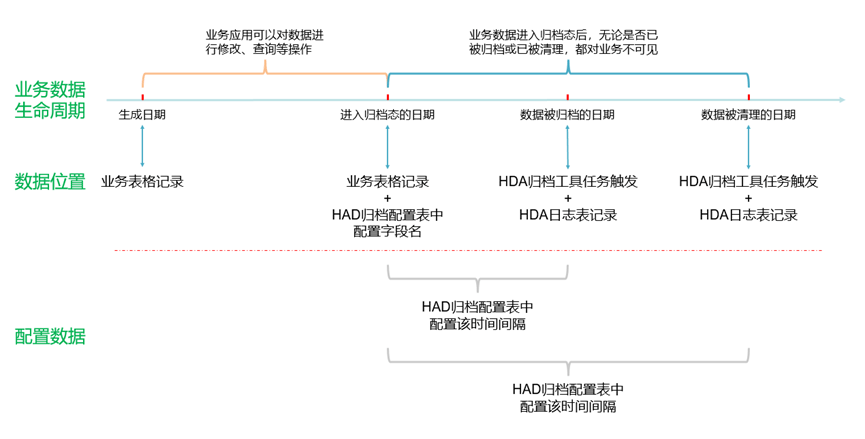
对于归档的数据按照数据库、表名和归档时间分目录存放,数据支持本地存储、通过sftp上传到指定的文件服务器或上传到指定的对象存储服务器。
总体流程图下图: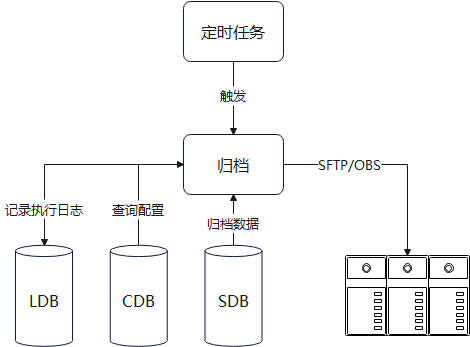
具体实现
执行之前有一个防并发的判断,因为该接口也可以手动调用,为了防止多次同时调用触发归档任务,所以有一个防并发的判断,然后初始化一些必要的参数,比如任务id,数据源配置,线程池配置,文件存储的配置,全局截止时间的获取等。
然后查询归档配置表的数据,得到所有要归档和清理的表,使用CountDownLatch作为一个全局标志,判断是不是所有的任务都执行完毕了。这里构造CountDownLatch的参数是所有任务的数量,将构造好的CountDownLatch对象传入每个任务中去,任务执行完后调用该对象的countDown方法,可以将其count值减一,当count值减到0之后代表所有的任务都执行完毕了。
然后将这些任务按服务进行分组,以服务名称作为区分,为其分配不同的线程池来执行归档或清理任务,然后再将这一个服务中的所有任务添加到一个list中,遍历这个list就可以启动对应的归档或清理任务了。
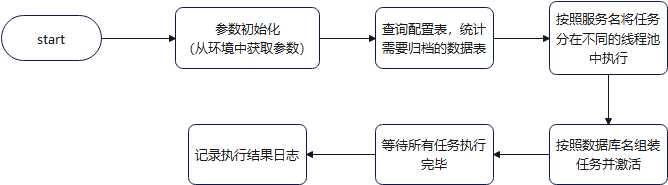
这里的任务主要分为两种,分别是归档任务和清理任务,这两个任务类基于模板设计的,用一个抽象类作为模板,两个子类分别继承该抽象类补充其中的关键步骤。
异常处理
归档工具未能在业务闲时运行完,影响了业务的正常运行,为避免这种情况,需要对归档工具设置截止时间,包括全局截止时间和优雅退出时间,均在配置文件中可以根据需求进行配置。
- 全局截止时间是绝对的时间,例如5:00或6:00。表示到该时间后不能再开启新的归档或清理任务,并将正在进行的归档后清理任务进行优雅停止。
- 优雅退出时间为时间间隔,单位是分钟,例如设置30分钟。表示系统达到全局截止时间+优雅推出时间时,如果仍有任务未完成,则需要强制执行结束动作。
具体实现:
在每个原子任务中,都需要检查是否到了全局截止时间:如果没到,继续进行当前任务;如果已经到了全局截止时间,则不再开启新的任务,当前正在进行的任务执行优雅退出。
另外,需要起一个监控线程,监控归档和清理任务是否已结束。当系统时间到达“全局截止时间+优雅退出余时间”时,还仍有归档或清理任务没有结束,则执行强制结束动作。归档时间范围确定
通过日志确定上次归档的日期,从上次的日期一直到要归档的时间开始,都是需要归档的数据